
生产实习记录
生产实习记录
2023年6月学校安排去中软国际下属的一家公司进行生产实习。
个人觉得这次实习还是蛮有意思的:一个Hadoop开发项目。但首先于时间和参与项目的队友编程能力,在一点遗憾中结束了这次生产实习。
现在记录下当时的踩坑记录
Hadoop学习
在Windows下配置Hadoop环境的注意事项
1 | 将C:\PROGRA~1\Java\jdk1.7.0_67 改为 D:\Softwares\jdk1.8(在环境变量设置中JAVA_HOME的值)(如果路径中有“Program Files”,则将Program Files改为 PROGRA~1) |
看完教程后嫌麻烦,还是VMware装三台CentOS 7虚拟机完成Hadoop集群搭建。
搭建完成后,使用jps命令查看运行情况
Idea Hadoop配置
Windows:IDEA配置Maven、Hadoop详细教程
1 | hadoop namenode -format |
1 | export HADOOP_HOME=/root/hadoop-2.10.2 |
HDFS指令
1 | hadoop fs -ls /test |
等价于
1 | hadoop fs -ls hdfs:///test |
1 | hadoop fs -mkdir |
直接访问本机文件系统
1 | hadoop fs -ls file:///root |
下面的操作基本就和Linux的Shell命令差不多,CSDN和博客园哪些那些记录的更加详细
1 | hadoop fs -mkdir |
1 | hadoop fs -touchz |
1 | hadoop fs -cat |
1 | hadoop fs -cp file:///root/1.txt /test/ |
1 | hadoop fs -appendToFile <local> <remote> |
MapReduce基本概念
map:分开计算
shuffle:将map结果分组,排序整理
reduce:统计
shuffle = map.shuffle + reduce.shuffle
reduce的shuffle不需要编程
MapReduce操作
数据类型
数字型
框架需要对key和value的类(classes)进行序列化操作,因此,这些类需要实现Writable接口。
另外,为了方便框架执行排序操作,key类必须实现WritableComparable接口。Hadoop定义的数字类型有BooleanWritable,ByteWritable, IntWritable, LongWritable,FloatWritable,DoubleWritable 分别对应:boolean,byte,int, long, float, double 基本类型。这些类中,都有一个get()方法得到基础类型的值,它们的构造器参数可以是其对应的基础类型的值。如:
1 | IntWritable value = new IntWritable(123); |
字符型
Text 是Hadoop定义的字符类型,对应 String。如:
1 | Text value = new Text("abc"); //创建Text类型数据 |
Example
需要一个Mapper和Reducer
Mapper
以键值对的方式读取
extends Mapper<LongWritable, Text, Text, IntWritable>
1 | public class Test { |
Reducer
1 | /** |
Job实现
在Hadoop 2中,MapReduce是一种分布式处理框架,用于处理大规模数据集的计算任务。一个MapReduce作业由多个Map阶段和一个Reduce阶段组成,它们可以在集群中并行执行。
org.apache.hadoop.mapreduce.Job类是Hadoop中表示一个MapReduce作业的主要类。以下是关于Job类的一些重要方法和概念:
- 创建Job对象:使用
Job.getInstance()方法创建一个Job对象,并指定所在的集群和配置。 - 设置输入和输出路径:使用
Job.setInputFormatClass()方法指定输入文件的格式以及用FileInputFormat设置输入路径,使用Job.setOutputFormatClass()方法指定输出文件的格式以及用FileOutputFormat设置输出路径。 - 设置Mapper和Reducer类:使用
Job.setMapperClass()和Job.setReducerClass()方法设置自定义的Mapper和Reducer类。 - 设置Mapper和Reducer的输出键值对类型:使用
Job.setMapOutputKeyClass()和Job.setMapOutputValueClass()方法设置Mapper的输出键值对类型,使用Job.setOutputKeyClass()和Job.setOutputValueClass()方法设置Reducer的输出键值对类型。 - 设置要使用的资源文件和库文件:使用
Job.addFileToClassPath()方法添加要使用的资源文件、Job.addArchiveToClassPath()方法添加要使用的压缩库文件。 - 提交作业并等待完成:使用
Job.waitForCompletion()方法提交作业,并等待作业完成。
在 Hadoop 中,job.setInputFormatClass() 用于指定输入数据的格式。参数常见如下:
TextInputFormat:将输入文件视为逐行文本文件。KeyValueInputFormat:将输入文件视为键值对(key-value)文件。SequenceFileInputFormat:将输入文件视为序列文件,其中包含键值对数据。CombineTextInputFormat:类似于TextInputFormat,但在处理大型文本文件时能够更好地利用 Hadoop 的InputSplit功能。NLineInputFormat:根据指定的行数将输入文件划分为InputSplit。CustomInputFormat:根据用户的需求自定义的输入格式。
这只是一些常见的输入格式类,实际上还可以根据需要自定义输入格式类来满足特定的需求。
1 | package org.example; |
执行程序
1 | hadoop jar *****.jar your.package.name.YourMainClas |
Hive操作
Hive数据仓库
数据仓库主要面对OLAP(联机分析处理),侧重决策分析。
Hive是依赖于Hadoop存在的,其次因为MapReduce语法较复杂,Hive可以将较简单的SQL语句转化成MapReduce进行计算!!!
[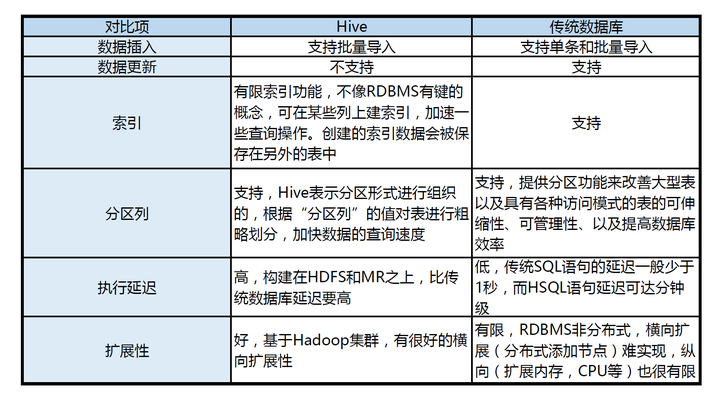 ]
]
Mahout提供一些可扩展的机器学习领域的经典算法实现,用于创建商务智能(BI)应用程序
Beeline
Hive客户端工具后续将使用Beeline 替代HiveCLI ,并且后续版本也会废弃掉HiveCLI 客户端工具,Beeline是 Hive 0.11版本引入的新命令行客户端工具,它是基于SQLLine CLI的JDBC客户
数据初始化
1 | schematool -initSchema -dbType mysql |
启动
两者,要么挂screen,要么挂hiveserver2
1 | hive --service metastore |
Hive获取Mysql元数据的两种方式:
①Hive直连MySQL获取元数据
启动方式:只需直接启动Hive客户端,即可连接
②Hive先连接Metastore服务,再通过 Metastore服务连接MySQL获取元数据
hive比较特殊,它既是自己的客户端,又是服务端。Hive充当客户端(是HDFS的客户端也是Metastore的客户端,也是Hive的客户端)又充当服务端(因为有Metastore服务和Hiveserver2服务配置)
因为在实际生产环境下,可能有多台Hive客户端(比如有:103、104、105三台机器),MySQL的 IP地址对外不暴露,只暴露给其中一台(假如暴露给103这台机器),那么其他客户端怎么连接呢?那么就需要在暴露的那台机器上启动Metastore服务,其他Hive客户端连接这个Metastore服务,进而达到连接Mysql获取元数据的目的。
hive是hadoop的客户端,同时hive本身也有客户端,Hiveserver2的beeline连接方式实际是Hive与Hive之间的服务端与客户端通过JDBC连接的方式
hiveserver2
HiveServer 是 Hive 的一个组件,它是 Hive 提供给外部客户端连接和交互的接口。HiveServer 允许用户通过各种编程语言(如 Java、Python、PHP 等)或工具(如 JDBC、ODBC 驱动)连接到 Hive,并执行 Hive 查询、操作数据等操作。
HiveServer 提供了两种不同的实现方式:
HiveServer1:HiveServer1 是旧版本的 HiveServer,它使用 Thrift 作为通信协议。HiveServer1 支持 Hive CLI 和其他的 Thrift 客户端连接,但不支持 JDBC 和 ODBC 连接。
HiveServer2:HiveServer2 是新版本的 HiveServer,它使用了更高级的 Thrift 通信协议,并提供了更多的功能和可扩展性。HiveServer2 支持 JDBC 和 ODBC 连接,可以通过各种编程语言和工具连接到 Hive 进行查询和操作。
使用 HiveServer,你可以将 Hive 集成到你的应用程序中,通过编程方式连接到 Hive 并执行 Hive 查询。这样,你可以使用 Hive 的强大的数据处理能力和 SQL 查询语言来处理大规模数据集。
在配置和使用 HiveServer 时,你需要指定 HiveServer 的监听地址、端口号、认证方式等配置,并确保 HiveServer 进程正在运行。一旦 HiveServer 运行起来,你就可以通过指定的连接方式和参数来连接到 HiveServer,并执行查询和操作。
Metastore
Hive 的 Metastore(元数据存储)是 Hive 的一个重要组件,它负责管理和存储 Hive 的元数据信息。元数据是描述数据的数据,它包含了表、分区、列、数据类型、表结构、表之间的关系等信息。
Hive 的 Metastore 将元数据存储在持久化的存储介质中,通常是一个关系型数据库(如 MySQL、PostgreSQL 等)。Metastore 将 Hive 的元数据信息组织成一个层次结构,包含数据库(database)、表(table)、分区(partition)等对象。
Metastore 提供了一组 API 和命令,用于管理和操作 Hive 的元数据。它负责处理表的创建、修改、删除,以及对表的元数据进行查询、检索等操作。Metastore 还支持表的分区管理,可以将表分成多个分区,每个分区可以根据不同的条件进行划分和管理。
Metastore 的主要功能包括:
元数据存储:Metastore 将 Hive 的元数据信息存储在持久化的存储介质中,以便在需要时进行检索和查询。
元数据管理:Metastore 提供了 API 和命令,用于管理和操作 Hive 的元数据。它可以创建、修改、删除表,管理分区等操作。
元数据查询:Metastore 提供了查询接口,可以根据条件查询表的元数据信息,如表的结构、列的属性等。
分区管理:Metastore 支持表的分区管理,可以将表分成多个分区,每个分区可以根据不同的条件进行划分和管理。
通过 Metastore,Hive 可以方便地管理和操作元数据信息,使得用户可以使用类似于 SQL 的语法来查询和操作大规模数据集。同时,Metastore 的使用还提高了 Hive 查询的性能,因为 Hive 可以利用元数据信息来进行查询优化和执行计划的生成。
HiveQL
Hadoop Hive(简称Hive)是一个基于Hadoop的数据仓库工具,它提供了一个类似于SQL的查询语言(HiveQL),用于处理和分析大规模的结构化和半结构化数据。
Hive 是为了方便数据分析人员使用 SQL 类似的查询语言来处理大规模数据而设计的,它将 SQL 查询转换为 Hadoop MapReduce 任务来执行。因此,Hive 可以让非程序员也能够使用 SQL 类似的语法来查询和分析大规模数据,而无需编写复杂的 MapReduce 程序。
Hive 使用 HiveQL(Hive Query Language)作为查询语言,HiveQL 类似于 SQL,但在语法和功能上有一些差异。HiveQL 支持常见的 SQL 操作,如 SELECT、JOIN、GROUP BY、WHERE 等,同时还支持用户自定义函数(UDF)、分区表、存储格式等特性。
Hive 的底层数据存储在 Hadoop 分布式文件系统(HDFS)中,并通过 Hive 的元数据存储(Metastore)来管理和查询数据的元数据信息。Hive 将数据存储为表的形式,表可以分成多个分区,每个分区可以根据不同的条件进行划分和管理。
使用 Hive,你可以通过 HiveQL 查询和分析大规模数据,利用 Hadoop 的并行计算能力来加速数据处理。Hive 还提供了丰富的内置函数和扩展功能,使得数据分析更加灵活和高效。
需要注意的是,Hive 不适用于实时数据处理和低延迟查询,因为它是基于批处理的模型。如果需要实时数据处理,可以考虑使用类似于 Apache Spark 的流式处理框架。
Hive中的表不支持直接定义主键约束,因为Hive是一个基于Hadoop的数据仓库系统,它的主要目标是提供大规模数据存储和查询的功能,而不是提供完整的事务支持。
表创建测试
1 | CREATE TABLE IF NOT EXISTS test_table ( |
default创建的表,会直接放在warehouse下边
在创建Hive表时,默认行分隔符”^A”,列分隔符”\n”,这两项也是可以设置的。在实际开发中,一般默认使用默认的分隔符,当然有些场景下也会自定义分隔符。
数据行可能是单个文件(甚至可以以文本形式打开)
1 | ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' |
查看表的数据属性
1 | desc table_3 |
创建新表
1 | create table table_3 as select name from test_table |
删库
1 | drop database db_1 |
查看表
1 | SELECT * from test_table limit 2 |
DML处理
数据源导入
1 | LOAD DATA LOCAL INPATH '/root/abcd.txt' into db.table_2 |
将文件中的数据导入(Load)到 Hive 表中
直接insert
1 | INSERT INTO test_table VALUES (1, 'John'); |
连接JDBC
与springboot貌似有依赖冲突,可能还有hive-common
1 | <dependency> |
select操作
1 | select concat("abcd","efgh") |
1 | SELECT nv1(NULL, "abcd"); |
NVL函数的功能是实现空值的转换,根据第一个表达式的值是否为空值来返回相应的列名或表达式,主要用于对数据列上的空值进行处理,语法格式如
Hive实现WordCount
在Hive中实现WordCount算法可以通过以下步骤:
- 创建一个包含文本数据的表:首先,使用Hive创建一个包含文本数据的表,其中每一行表示一个文本文件中的内容,每个单词用空格或其他分隔符分隔。你可以使用如下的Hive语句创建表:
1 | CREATE TABLE text_data (line STRING); |
- 导入文本数据:使用Hive的
LOAD DATA命令将文本数据导入到上述的text_data表中。假设数据文件data.txt包含文本数据,可以使用如下命令导入数据:
1 | LOAD DATA INPATH '/data.txt' INTO TABLE text_data; |
- 编写WordCount查询:使用Hive的查询语法编写WordCount查询。以下是一个示例查询,可以计算每个单词的出现次数:
1 | SELECT word, COUNT(*) AS count |
上述查询中,首先使用split函数将每一行的内容拆分成单词,并使用explode函数将拆分后的单词展开成多个行。然后,将结果进行分组、计数和排序,以得到每个单词的出现次数。
- 运行查询:在Hive中运行上述查询,并查看结果。你可以使用Hive的命令行界面或其他Hive客户端运行查询。
请注意,为了更准确地进行WordCount,你可能需要进行一些文本处理和清洗操作,如删除标点符号、转换为小写等。你可以根据具体需求进行适当的修改。
貌似Druid可以统一MySQL与Hive
Druid
本来准备计划试试,但自己SpringBoot学艺不精,再加上最后选用了Django,项目后期就没有在考虑了
druid-spring-boot-starter整合hive遇到的一个小坑
Sqoop
Sqoop 2021年停止维护
我看组员最后数据分析用了SPSSPRO
PyHive
1 | pip install sasl |
但Windows下安装报错
1 | C:\Users\Administrator\AppData\Local\Temp\pip-install-7_4i0p52\sasl_bd6a6fbee8074cf6814556fa3e26c960\sasl\saslwrapper.h(22): fatal error C1083: 无法打开包括文件: “sasl/sasl.h”: No such file or directory |
最后证明PyHive依赖于Linux的组件,在Ubuntu上运行起来了
insert overwrite操作
1 | select * from emp; |
在Hive中,DELETE操作的替代方式是使用INSERT INTO语句将要保留的数据插入到新的表中,然后重命名新表覆盖原始表。这种方式被称为“Insert-Overwrite”。
1 | insert overwrite table order |
Centos踩坑
ssh登录过慢
1 | 1.su (以root用户登录) |
Themlef
最后项目结束答辩的其中一个成果,是做页面进行数据展示。整个小组里只有我能完成前端与后端的工作,为了省时间就只能选前后端一体的方案。SpringBoot+Themlef是我当时比较中意的一个方案
需要starter-web
1 | <dependency> |
Layui
如果前后端是一体的话推荐使用这个
启动配置
SpringBoot整合Thymeleaf快速入门(附详细教程)
准表达式语法
Thymeleaf 模板引擎支持多种表达式:
- 变量表达式:${…}
- 选择变量表达式:*{…}
- 链接表达式:@{…}
- 国际化表达式:#{…}
- 片段引用表达式:~{…}
① 获取对象的属性和方法
使用变量表达式可以获取对象的属性和方法,例如,获取 person 对象的 lastName 属性,表达式形式如下:
1 | ${person.lastName} |
② 使用内置的基本对象
使用变量表达式还可以使用内置基本对象,获取内置对象的属性,调用内置对象的方法。 Thymeleaf 中常用的内置基本对象如下:
- #ctx :上下文对象;
- #vars :上下文变量;
- #locale:上下文的语言环境;
- #request:HttpServletRequest 对象(仅在 Web 应用中可用);
- #response:HttpServletResponse 对象(仅在 Web 应用中可用);
- #session:HttpSession 对象(仅在 Web 应用中可用);
- #servletContext:ServletContext 对象(仅在 Web 应用中可用)。
例如,我们通过以下 2 种形式,都可以获取到 session 对象中的 map 属性:
1 | ${#session.getAttribute('map')}${session.map} |
③ 使用内置的工具对象
除了能使用内置的基本对象外,变量表达式还可以使用一些内置的工具对象。
- strings:字符串工具对象,常用方法有:equals、equalsIgnoreCase、length、trim、toUpperCase、toLowerCase、indexOf、substring、replace、startsWith、endsWith,contains 和 containsIgnoreCase 等;
- numbers:数字工具对象,常用的方法有:formatDecimal 等;
- bools:布尔工具对象,常用的方法有:isTrue 和 isFalse 等;
- arrays:数组工具对象,常用的方法有:toArray、length、isEmpty、contains 和 containsAll 等;
- lists/sets:List/Set 集合工具对象,常用的方法有:toList、size、isEmpty、contains、containsAll 和 sort 等;
- maps:Map 集合工具对象,常用的方法有:size、isEmpty、containsKey 和 containsValue 等;
- dates:日期工具对象,常用的方法有:format、year、month、hour 和 createNow 等。
例如,我们可以使用内置工具对象 strings 的 equals 方法,来判断字符串与对象的某个属性是否相等,代码如下。
1 | 纯文本复制 |
与js结合
必须单独创建一个变量
1 | <script th:inline="javascript"> |
或者用each
1 | <tr th:each="book : ${books}"> |
th语法
| 属性 | 描述 | 示例 |
|---|---|---|
| th:id | 替换 HTML 的 id 属性 | <input id="html-id" th:id="thymeleaf-id" /> |
| th:text | 文本替换,转义特殊字符 | <h1 th:text="hello,bianchengbang" >hello</h1> |
| th:utext | 文本替换,不转义特殊字符 | <div th:utext="'<h1>欢迎来到编程帮!</h1>'" >欢迎你</div> |
| th:object | 在父标签选择对象,子标签使用 *{…} 选择表达式选取值。 没有选择对象,那子标签使用选择表达式和 ${…} 变量表达式是一样的效果。 同时即使选择了对象,子标签仍然可以使用变量表达式。 | <div th:object="${session.user}" > <p th:text="*{fisrtName}">firstname</p></div> |
| th:value | 替换 value 属性 | <input th:value = "${user.name}" /> |
| th:with | 局部变量赋值运算 | <div th:with="isEvens = ${prodStat.count}%2 == 0" th:text="${isEvens}"></div> |
| th:style | 设置样式 | <div th:style="'color:#F00; font-weight:bold'">编程帮 www.biancheng.net</div> |
| th:onclick | 点击事件 | <td th:onclick = "'getInfo()'"></td> |
| th:each | 遍历,支持 Iterable、Map、数组等。 | <table> <tr th:each="m:${session.map}"> <td th:text="${m.getKey()}"></td> <td th:text="${m.getValue()}"></td> </tr></table> |
| th:if | 根据条件判断是否需要展示此标签 | <a th:if ="${userId == collect.userId}"> |
| th:unless | 和 th:if 判断相反,满足条件时不显示 | <div th:unless="${m.getKey()=='name'}" ></div> |
| th:switch | 与 Java 的 switch case语句类似 通常与 th:case 配合使用,根据不同的条件展示不同的内容 | <div th:switch="${name}"> <span th:case="a">编程帮</span> <span th:case="b">www.biancheng.net</span></div> |
| th:fragment | 模板布局,类似 JSP 的 tag,用来定义一段被引用或包含的模板片段 | <footer th:fragment="footer">插入的内容</footer> |
| th:insert | 布局标签; 将使用 th:fragment 属性指定的模板片段(包含标签)插入到当前标签中。 | <div th:insert="commons/bar::footer"></div> |
| th:replace | 布局标签; 使用 th:fragment 属性指定的模板片段(包含标签)替换当前整个标签。 | <div th:replace="commons/bar::footer"></div> |
| th:selected | select 选择框选中 | <select> <option>---</option> <option th:selected="${name=='a'}"> 编程帮 </option> <option th:selected="${name=='b'}"> www.biancheng.net </option></select> |
| th:src | 替换 HTML 中的 src 属性 | <img th:src="@{/asserts/img/bootstrap-solid.svg}" src="asserts/img/bootstrap-solid.svg" /> |
| th:inline | 内联属性; 该属性有 text、none、javascript 三种取值, 在 评论 数据库加载中 |




